O11ySources
Introduction
Welcome to the O11ySources User Guide, your comprehensive reference for managing and onboarding observability integrations within the vuSmartMaps™ platform. An O11ySource represents a supported integration or component type that defines what kind of observability data can be collected, such as from applications, databases, servers, cloud services, or network infrastructure. Each O11ySource provides the structure, capabilities, and configuration options required to onboard data into the platform.
Within an O11ySource, one or more Source Instances are configured to represent where the data is collected from. A Source Instance corresponds to a specific target endpoint and is responsible for actively sending observability data into vuSmartMaps. By leveraging O11ySources and their associated Source Instances, you can seamlessly onboard, monitor, and analyze diverse observability data streams. This enables you to gain deep insights into system performance, detect issues early, and maintain optimal operational efficiency. Whether you are monitoring metrics, collecting logs, or visualizing operational trends, O11ySources provide a centralized and consistent framework to manage data onboarding and ensure reliable, end-to-end observability across your environment.
Data Onboarding with O11ySources
O11ySources simplify the data onboarding process in vuSmartMaps by providing a structured and consistent way to define, configure, and activate observability data collection across different systems. Data onboarding begins by selecting and enabling an O11ySource, which defines the type of integration and the kind of data that can be collected. Once an O11ySource is enabled, one or more Source Instances are configured to represent the actual targets from which data is collected.
The onboarding workflow follows this sequence:
- Enable O11ySource: An O11ySource is enabled to make its configuration and data collection capabilities available within the platform.
- Configure Source Instances: Source Instances are created and configured by specifying the target endpoint and defining how data should be collected. During this step, users choose the appropriate management method for each Source Instance, such as OmniAgent-based collection, remote collection, or manual setup, depending on the O11ySource capabilities.
- Initiate Data Collection: Once Source Instances are configured and validated, data collection begins based on the selected management method and configuration parameters.
- Process and Enrich Data: The collected data flows through processing pipelines where it is transformed, enriched with contextual information, and prepared for storage.
- Visualize and Act on Data: The processed data is made available for dashboards, storyboards, and alert rules, enabling real-time observability, historical analysis, and proactive monitoring.
This structured onboarding approach ensures a clear setup sequence, reduces configuration errors, and provides reliable visibility across your environment, forming the foundation of an efficient and scalable observability ecosystem.
Data Flow Journey
This section explains how observability data flows through vuSmartMaps, from the point at which a Source Instance is configured to the point at which insights are consumed through visualizations and alerts.
The data flow journey consists of the following key stages:
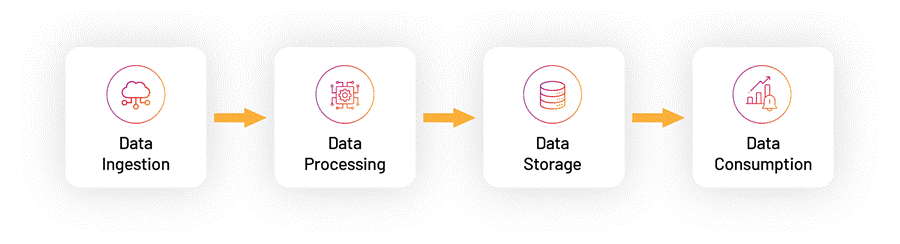
Data Ingestion
- Data ingestion begins after a Source Instance is configured and activated within an O11ySource. Data is collected from the configured Source Instances using one of the supported collection mechanisms, OmniAgent-based collection, remote collection, or manual setup.
- The collection method used depends on the O11ySource capabilities and the configuration selected for each Source Instance. Once collection starts, data is securely ingested into the platform for further processing.
Data Processing
After ingestion, data is processed through the ContextStreams module. ContextStreams manages the complete data processing workflow, including:
- Input streams that receive data from Source Instances
- Pipelines that perform transformations, filtering, and enrichment
- Output streams that route processed data to downstream systems
This stage enriches raw data with context and structure, enabling accurate analysis and efficient downstream consumption.
Data Storage
- The processed data is stored in Hyperscale and Postgres data stores.
- These storage layers are optimized to support both high-volume data ingestion and fast query performance, forming the foundation for analytics, dashboards, and alerting capabilities within vuSmartMaps.
Data Consumption
In the final stage, stored data is consumed through dashboards, storyboards, alerts, and reports. This is where users interact with the data to:
- Monitor system health and performance
- Analyze trends and anomalies
- Receive proactive alerts
- Make informed operational decisions using both real-time and historical data
To fully leverage the O11ySource framework, the journey begins with enabling an O11ySource and configuring the required Source Instances. This guide walks you through each stage of the process, helping you understand how data flows through the platform and how each component contributes to reliable, end-to-end observability.
